エクスポートした文字列テーブルファイル(*.txtまたは*.csv)のフォーマットは次のようになります。
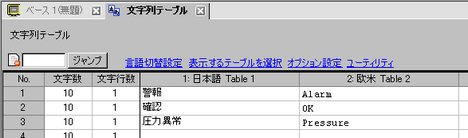
文字列テーブル登録画面
CSVファイルフォーマット(カンマ区切り)
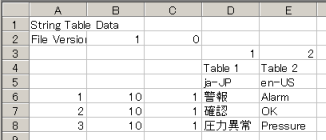
String Table Data
File Version,1,0
,"","","1","2"
,"","","Table 1","Table 2"
,"","","ja-JP","en-US"
1,"10","1"," 警報 ","Alarm"
2,"10","1"," 確認 ","OK"
3,"10","1"," 圧力異常 ","Pressure"
String
Table Data
ヘッダー(インポートする際に必要です)
File
Version
ファイルのバージョン情報
エクスポートすると自動で設定されます
,"","","1","2"
各テーブルのテーブル番号
,"","","Table
1","Table 2"
各テーブルのテーブル名
,"","","ja-JP","en-US"
各テーブルの言語コード *1
1,"10","1","警報","Alarm"
No.1の文字数、文字行数、各テーブルの文字列
2,"10","1","確認","OK"
No.2の文字数、文字行数、各テーブルの文字列
3,"10","1","圧力異常","Pressure"
No.3の文字数、文字行数、各テーブルの文字列
![]()
ダブルクォーテーションに囲まれた文字列はダブルクォーテーションを文字列とは認識しません。
例 : "警報"→ 警報
ダブルクォーテーションを文字列に反映させたい場合は、ダブルクォーテーションを2つ続けて記述してください。
例 : "警""報"→ 警"報
連続しないダブルクォーテーションは、データとして認識されません。
例 : ""警報""→ 警報
"""警報""" → "警報"
"警"報"→ 警報
各レコードの終端は、改行コードまたはファイルの終わりで判断されます。ただしダブルクォーテーションに囲まれた位置に改行コードがある場合は、レコードの終端コードとしてではなく、文字列として認識されます。
例 : "警報"<改行コード> → 改行コードはレコードの終端として認識されます。
"警報<改行コード>" → 改行コードはレコードの終端として認識されません。
前述のCSVファイルをExcelで開いた場合、以下のようになります。
![]()
入力した文字優先で設定している場合は、文字数と文字行数の設定値を超えても入力した内容がそのままエクスポートされます。
ファイルフォーマットを変更すると正しく更新されません。
インデックス番号も昇順のままで並び替えないでください。
*1文字列テーブルファイル(*.txtまたは*.csv)では、各テーブルの言語は次の言語コードで表示されます。
言語 |
言語コード |
日本語 |
ja-JP |
欧米 |
en-US |
中国語(繁体字) |
zh-TW |
中国語(簡体字) |
zh-CN |
韓国語 |
ko-KR |
ロシア語(キリル) |
ru-ru |
タイ語 |
th-TH |